The AI told your CFO that Q3 revenue was $14.2 million. The real number was $11.8 million. No disclaimer. No hedge. No source citation. A wrong number delivered with the confidence of a senior analyst who has been with the company for twenty years. That moment, when AI hallucinations meet financial decisions, is the reason you are reading this.
The gap between what AI says and what is true is not a software bug. It is a structural property of how large language models work. They predict the next most probable word. They do not verify facts. They do not check your general ledger. They do not know the difference between your Q3 and someone else’s. Which means the fix is not a better prompt. The fix is architectural.
Table of Contents
What AI hallucination is, in one paragraph
A confident, fluent answer that is factually incorrect or unsupported by source data. The grammar is flawless. The tone is assured. The content is fabricated, distorted, or pulled from the wrong context. Hallucinations are not edge cases. They are predictable behavior from any system that generates language through statistical pattern matching rather than factual retrieval.
The model is not lying. It is not broken. It is doing exactly what it was built to do: predict the next word. The problem is that word prediction and truth are not the same thing. Recognizing that gap is step one toward building AI safe for business-critical decisions.
Why hallucination matters more in business than in consumer AI
A hallucinated recipe is a bad dinner. A hallucinated margin figure is a bad quarter.
The cost is measured in dollars
When an AI agent surfaces a fabricated cost figure in an FP&A workflow, someone acts on it. Budgets get set. Headcount gets approved. Capital gets allocated. The risk surface is widening: Gartner projects that more than 40% of AI-related data breaches by 2027 will arise from the improper cross-border use of generative AI. In finance, every AI incident translates to money lost on bad data, regulatory exposure, or both.
Regulators do not accept “the AI said so”
Audit committees, regulators, and boards require traceable justification for financial decisions. “The AI said so” is not a defensible answer. Every output must trace back to a verifiable source. Without that chain of evidence, you are exposed on compliance, on audit, and on fiduciary duty.
The trust deficit compounds
One hallucinated number does not just create one bad decision. It poisons confidence in every subsequent AI output. Operations stops trusting the AI. Finance builds shadow spreadsheets to double-check every answer. The productivity gains that justified the AI investment evaporate. The trust deficit compounds faster than any ROI model accounts for.
The four architectural approaches to mitigate AI hallucinations
Better prompts help at the margins. Better architecture changes the structural conditions that produce hallucinations in the first place. When AI agents operate autonomously, architecture is the only reliable safeguard. Four approaches dominate serious enterprise deployments. Most production systems combine two or more.
Retrieval-augmented generation (RAG)
RAG grounds LLM responses in retrieved documents. The system searches a knowledge base, feeds relevant documents into the prompt context, and the model generates a response anchored to those documents rather than training data.
Strong for unstructured data: policy documents, contracts, internal wikis, research reports. Weaker for transactional data. When a CFO asks “what was our gross margin in Q3 by product line?”, there is no document to retrieve. The answer lives in structured tables across multiple systems. RAG alone cannot ground that.
RAG also introduces retrieval quality as a new failure mode. If the retrieval step surfaces the wrong document, the model hallucinates with even more confidence because it now has a “source.”
Semantic-layer grounding
A semantic layer anchors the AI in a defined business vocabulary. Instead of letting the model interpret “revenue” or “customer” based on generic training data, the layer defines exactly what those terms mean in your business. The model reasons in your concepts, not its own.
Strong for consistent metric definitions and governed data. Prevents the class of hallucination where the model uses the right word but the wrong definition. When your “revenue” includes deferred revenue and the model’s “revenue” does not, the semantic layer catches the mismatch before it becomes a wrong answer.
Ontology and digital-twin grounding
The strongest structural approach is an ontology. A business ontology maps every entity, transaction, relationship, and rule into a formal knowledge graph. The AI does not predict answers. It retrieves them from a live, structured representation of reality.
This is where explainable AI moves from theory to practice. When the AI answers by traversing an ontology, every step is traceable. You see which entities it referenced, which relationships it followed, which transactions it aggregated. Not a black box. An auditable path.
Ontology grounding handles structured and unstructured data. Handles transactional queries that break RAG. Handles ambiguous terminology that breaks basic prompting. The tradeoff: building one requires upfront investment in modeling your operations accurately.
Human-in-the-loop verification
For high-stakes outputs, human review remains necessary regardless of which grounding approach you use. No architecture eliminates hallucination to zero. The loop adds a checkpoint where a domain expert validates the AI output before it reaches a decision-maker.
The key is designing the loop well. A human reviewing 500 AI outputs per day with no context about how each was generated is not verification. It is theater. Effective human-in-the-loop requires the AI to surface its sources and reasoning so the reviewer can spot-check efficiently.
Where FreshBI fits: Ontology 1st Design as hallucination mitigation
FreshBI’s Ontology 1st Design starts with the ontology, not the model. Before any AI agent is deployed, FreshBI builds a Medallion Architecture data foundation that maps the customer’s entities, transactions, and business rules into a structured, governed layer.
Not a generic data warehouse with an AI wrapper. A purpose-built ontology that reflects how the specific business operates. FreshBI has deployed this for Wells Fargo, AIG, and Kaiser Permanente — environments where a hallucinated number is not embarrassing. It is a regulatory event.
The result is trustworthy AI in the operational sense. Not trustworthy because someone promised it. Trustworthy because every answer traces to a source transaction through a governed data layer.
When the requirement is bulletproof grounding — every AI answer traceable to a source transaction — FreshBI’s sister brand Truzer goes one step further. Truzer builds a live business ontology that updates as transactions happen, so every AI response is grounded in the current state of the business, not a snapshot. The ontology is the unified digital twin.
What comes after hallucination mitigation
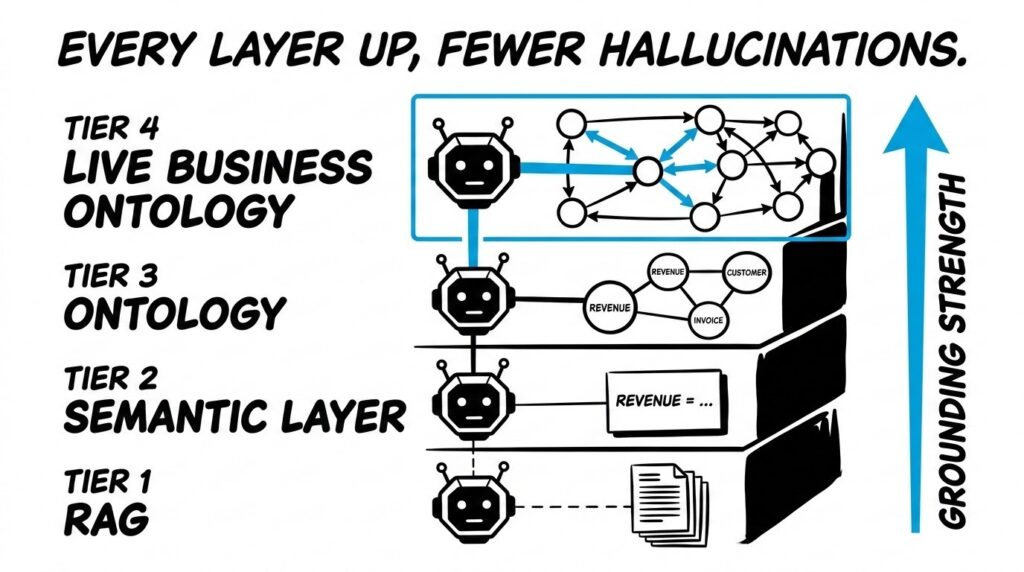
The progression from RAG to semantic layer to live ontology is a hierarchy of grounding strength. Each approach anchors the AI differently.
RAG grounds the model in documents. The model retrieves text and generates from it. Works when answers live in documents. Breaks when answers require computation across structured data or reasoning about entity relationships across systems.
Semantic-layer grounding adds a vocabulary layer. The model knows “revenue” in your business means a specific thing with specific inclusion and exclusion rules. Prevents definitional hallucination. But the semantic layer is a translation guide, not a live map of the business.
The live business ontology approach (Truzer) is the deepest grounding available. Every entity, transaction, relationship, and business rule mapped into a unified digital twin that updates continuously. The AI does not retrieve documents or translate terms. It traverses a live graph of the business itself.
When an executive asks “what is our margin exposure on the top 10 accounts this quarter?”, a RAG system searches for a document that contains the answer. A semantic layer ensures “margin” means the right thing. The live ontology computes the answer from current transactional data, traces the calculation path, and surfaces the source records. Scotiabank and other regulated institutions need that grounding to make AI defensible.
This is the architectural direction the industry is moving. Grounded in the ontology. Not hallucinated from generic training data.

The verdict and the next step
AI hallucinations are not a bug you patch. They are a structural property that requires architectural mitigation. Better prompts help at the margins. RAG helps for document-based answers. Semantic layers help for vocabulary consistency. The live business ontology provides the deepest grounding for transactional, multi-system business data.
Most organizations need a combination. The right one depends on your data landscape, your regulatory exposure, and the stakes of the decisions your AI agents inform. The wrong move is treating hallucination as someone else’s problem or assuming your LLM vendor has solved it. No model vendor has. The grounding has to happen in your architecture, against your data, anchored to your business reality.
The next step is a 60-minute conversation about your current AI risk surface. Where are your agents making decisions today? What grounding do they have? Where are the gaps between what the AI says and what is verifiably true? Our vendor evaluation framework covers what to ask before signing.
Book a call with FreshBI to map your hallucination risk and build the grounding architecture that makes AI safe for your business.
Frequently Asked Questions
How can we detect AI hallucinations before they reach executives or customers?
Automated checks that flag unsupported claims, missing citations, and numeric outputs that do not reconcile to a system of record. Route flagged responses to a review queue. Require a confidence and provenance summary before distribution.
What are the most common hallucination triggers?
Underspecified questions. Multiple systems with conflicting values. Calculations without a governed computation layer. Prompts that encourage speculation, like asking for estimates without defining acceptable assumptions.
How should we measure hallucination risk over time?
Citation coverage. Percent of answers fully traceable to approved sources. Rate of post hoc corrections found in audits or QA reviews. Pair with workflow impact: time-to-verify, escalations per business function.
What governance controls reduce hallucinations without slowing teams down?
Role-based access. Approved data sources. Pre-defined query templates for high-stakes domains like finance and compliance. Lightweight guardrails — mandatory citations, automated validation checks — so humans review exceptions instead of every response.
How do we choose which mitigation approach to apply to each use case?
Classify by data type (documents versus systems of record), decision criticality, and tolerance for uncertainty. Low-risk use cases can be more generative. High-risk workflows enforce strict source requirements and controlled computations.
How can we evaluate an AI vendor’s claims about being “hallucination-free”?
Ask for a live demo using your data that shows end-to-end provenance: which sources were used, how calculations were performed. Require evidence from red-team tests and failure reports, not accuracy claims on generic benchmarks.
What change-management steps help teams adopt grounded AI without losing trust?
A narrow pilot where outputs are easy to verify. Clear usage guidelines. Examples of both successes and caught failures. Reviewer training on efficient validation. A feedback loop so recurring error patterns lead to durable fixes in data and workflow design.